

Instantid Identity Preservation Image Generation
InstantID: Zero-shot Identity-Preserving Generation in Seconds
AI-powered image generation technologies have seen exponential growth recently with the advent of advanced text-to-image diffusion models like DALL-E, GLIDE, Stable Diffusion, Imagen, and others. These models, although differing in architecture and training approaches, converge on a single goal: to provide customized and personalized image creation. They strive to generate images that maintain a consistent character ID, subject, and style, based on reference images. These powerful generative tools have been deployed across various domains such as image animation, virtual reality, e-commerce, and AI-generated portraits. Despite their impressive capabilities, a common challenge persists across these models: they struggle to produce customized images that accurately preserve the intricate identity features of human subjects.
Generating customized images that capture intricate details, particularly in tasks involving human facial identity, demands a high level of fidelity and detail. This requirement is more pronounced than in general image generation tasks, which often focus on broader aspects like textures and colors. Recent advancements in personalized image synthesis frameworks, such as LoRA, DreamBooth, and Textual Inversion, have significantly pushed the boundaries. However, these personalized image generation AI models still face practical deployment challenges due to high storage demands, the necessity for multiple reference images, and extensive fine-tuning processes. In contrast, ID-embedding methods that utilize a single forward reference often struggle with compatibility with existing pre-trained models, require intensive parameter fine-tuning, or fail to maintain accurate facial fidelity.
To overcome these obstacles and enhance image generation capabilities, this article will discuss InstantID, a diffusion model-based solution for image generation. InstantID operates as a versatile, plug-and-play module that adeptly handles image generation and personalization using just a single reference image while ensuring high fidelity. Our primary goal is to equip our readers with a comprehensive understanding of InstantID's technical foundations, including its architecture, training process, and application scenarios. Let’s dive into the details.
The rise of text-to-image diffusion models has significantly advanced image generation technology. These models are designed to produce personalized and customized images, creating consistent visuals in terms of subject, style, and character ID, using one or more reference images. Their capacity to generate uniform images has opened up numerous possibilities across various sectors, including image animation, AI portrait creation, e-commerce, and virtual and augmented reality, among others.
Despite their impressive capabilities, text-to-image diffusion models face significant challenges in generating customized images that accurately preserve the intricate details of human subjects. Creating such detailed images is particularly demanding because human facial identity necessitates a higher degree of fidelity and more complex semantics compared to general objects or styles, which may primarily focus on colors or broader textures. These models rely on detailed textual descriptions to guide image generation, yet they often fall short in achieving strong semantic relevance for personalized imagery. Additionally, some advanced pre-trained text-to-image frameworks incorporate spatial conditioning controls, such as body poses, depth maps, user-drawn sketches, and semantic segmentation maps, to improve controllability and allow for finer structural adjustments. However, even with these advancements, the frameworks typically only achieve partial fidelity in replicating the reference image accurately.
To address these challenges, the InstantID framework emphasizes instant identity-preserving image synthesis, effectively balancing efficiency with high fidelity. It introduces a straightforward plug-and-play module that facilitates image personalization using just a single facial image while ensuring high fidelity. Moreover, the InstantID framework employs a novel face encoder that captures intricate details. This encoder enhances image generation by incorporating weak spatial and strong semantic conditions, guided by textual prompts, landmark images, and facial images.
Three key features distinguish the InstantID framework from other text-to-image generation technologies:
- Compatibility and Pluggability: Unlike methods that require extensive training on the full parameters of the UNet framework, InstantID trains a lightweight adapter, making it compatible and easily integrable with existing pre-trained models.
- Tuning-Free: InstantID's approach removes the need for fine-tuning, relying on a single forward propagation for inference. This makes the model both practical and cost-effective, minimizing the resources required for fine-tuning.
- Superior Performance: Demonstrating remarkable flexibility and fidelity, InstantID achieves state-of-the-art performance using only a single reference image. This level of performance is typically expected from training-based methods that utilize multiple references.
The contributions of the InstantID framework can be summarized as follows:
- InstantID is an innovative adaptation method for pre-trained text-to-image diffusion models, designed to preserve identity while optimizing the balance between efficiency and fidelity.
- The framework is compatible and can be seamlessly integrated with custom fine-tuned models that use the same diffusion model architecture. This allows for identity preservation in pre-trained models without incurring extra costs.
InstantID: Methodology and Architecture
The InstantID framework is a proficient lightweight adapter that seamlessly enhances pre-trained text-to-image diffusion models with ID preservation capabilities. Built atop the Stable Diffusion model, InstantID leverages its ability to perform diffusion processes efficiently in a low-dimensional latent space, rather than in pixel space, utilizing an autoencoder. When an image is inputted, its encoder maps the image to a latent representation characterized by downsampling factors and latent dimensions. The diffusion process then uses a denoising UNet component to reduce noise in the latent space, which is conditioned on normally distributed noise, the current timestep, and embeddings of textual prompts generated by a pre-trained CLIP text encoder.
Additionally, the InstantID framework incorporates a ControlNet component that adds spatial control to the diffusion process, significantly extending the capabilities beyond mere textual prompts. This component integrates with the UNet architecture from Stable Diffusion, employing a replicated UNet that features zero convolution layers in its middle and encoder blocks. Despite their similarities, ControlNet uniquely modifies the diffusion process by incorporating spatial conditions such as poses, depth maps, and sketches, integrating these elements into the UNet's block residuals and embedding them within the original network.
Inspired by the IP-Adapter or Image Prompt Adapter, the InstantID framework also introduces a novel methodology to enable image prompt capabilities in parallel with textual prompts, without altering the foundational text-to-image models. The IP-Adapter employs a distinctive decoupled cross-attention strategy, adding cross-attention layers that embed image features while leaving other model parameters unchanged. This innovative approach allows for a seamless integration of visual and textual data, enhancing the model's ability to generate images that closely adhere to both text and image prompts.
Methodology Overview
The InstantID framework is designed to generate customized images, capturing various styles or poses with a high degree of fidelity using just a single reference ID image. Below is a simplified diagram illustrating the key components of the InstantID framework.
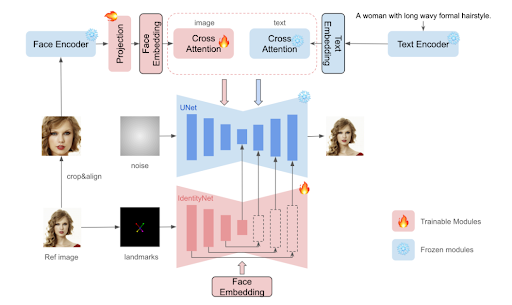
The framework is structured around three crucial components:
- ID Embedding Component: This captures the robust semantic information from the facial features present in the image, ensuring that key identity markers are retained.
- Lightweight Adapter Module: This includes a decoupled cross-attention component, enabling the use of an image as a visual prompt, thereby enhancing the model's responsiveness to visual data.
- IdentityNet Component: It encodes detailed features from the reference image, incorporating additional spatial controls to refine and maintain the identity details throughout the generation process.
ID Embedding
In contrast to existing methods such as FaceStudio, PhotoMaker, and IP-Adapter, which utilize a pre-trained CLIP image encoder to extract visual prompts, the InstantID framework places a greater emphasis on enhanced fidelity and more detailed semantic preservation in ID preservation tasks. It's important to highlight that the main limitation of the CLIP encoder stems from its training on weakly aligned data. This results in the encoder capturing broad and somewhat ambiguous semantic information like colors, style, and overall composition. While these features are useful for complementing text embeddings in general image generation tasks, they fall short in precise ID preservation tasks that require strong semantic detail and high fidelity.
Furthermore, advancements in face representation models, particularly in facial recognition research, have proven effective for complex tasks such as facial reconstruction and recognition. Building on these advancements, the InstantID framework seeks to utilize a pre-trained face model to detect and extract face ID embeddings from the reference image. This approach guides the image generation process, ensuring that the resulting images maintain a true representation of the individual's identity.
Image Adapter
Pre-trained text-to-image diffusion models greatly enhance image prompting capabilities, particularly in scenarios where text prompts alone cannot fully capture the desired details. The InstantID framework employs a strategy similar to the IP-Adapter model, which uses a lightweight adaptive module combined with a decoupled cross-attention component to facilitate the use of images as input prompts. Unlike the broader, more generalized CLIP embeddings, the InstantID framework takes a different approach by using ID embeddings as the image prompts. This shift aims to achieve a richer and more nuanced integration of semantic details, enhancing the precision and relevance of the generated images.
IdentityNet
While existing methods can integrate image prompts with text prompts, the InstantID framework contends that these integrations typically enhance only the coarse-grained features, and do not achieve the depth of integration needed for ID-preserving image generation. Directly adding image and text tokens in cross-attention layers often dilutes the control exerted by text tokens. Attempts to strengthen the impact of image tokens may conversely diminish the text tokens' effectiveness in editing tasks.
To address these challenges, the InstantID framework adopts ControlNet, an alternative feature embedding method that uses spatial information as input for its controllable module. This approach ensures compatibility with the UNet settings in diffusion models, enhancing the precision of feature integration.
The InstantID framework introduces two significant modifications to the traditional ControlNet architecture: firstly, it uses 5 facial keypoints as conditional inputs instead of the more detailed OpenPose facial keypoints. Secondly, it employs ID embeddings rather than text prompts as the conditions for the cross-attention layers within the ControlNet structure. These changes aim to refine the specificity and relevance of the generated images while preserving identity features more effectively.
Training and Inference
In the training phase, the InstantID framework focuses on optimizing the parameters of IdentityNet and the Image Adapter, while keeping the parameters of the pre-trained diffusion model unchanged. The framework is trained using image-text pairs that depict human subjects, utilizing a training objective akin to that employed in the Stable Diffusion framework but tailored with task-specific image conditions. A key aspect of the InstantID training methodology is the separation of the image and text cross-attention layers within the image prompt adapter. This strategic separation allows for flexible and independent adjustment of the weights for these image conditions. This approach ensures a more precise and controlled training and inference process, enhancing the framework’s ability to accurately generate images that preserve identity details.
InstantID: Experiments and Results
The InstantID framework leverages the Stable Diffusion model and conducts training on LAION-Face, a comprehensive open-source dataset containing over 50 million image-text pairs. To further refine the quality of image generation, the framework also gathers more than 10 million human images, with captions automatically generated by the BLIP2 model. Focusing predominantly on single-person images, InstantID employs a pre-trained face model to detect and extract face ID embeddings directly from these human images. Unlike other methods that train on cropped facial datasets, InstantID trains using the original, full human images.
During the training process, the framework maintains the pre-trained text-to-image model parameters static, only updating the parameters of IdentityNet and Image Adapter. This approach ensures that the core generative capabilities are preserved while enhancing the model’s ability to handle identity-specific details effectively.
Image-Only Generation
The InstantID model employs an empty prompt to facilitate the image generation process using solely the reference image. The effectiveness of this 'Empty Prompt' generation is illustrated in the following image:

This approach robustly maintains rich semantic facial features such as identity, age, and expression. However, it is important to note that using empty prompts might not accurately replicate other semantic attributes like gender. In the above image, columns 2 to 4 showcase the combination of an image and a prompt. As observed, there is no degradation in text control capabilities, and identity consistency is maintained throughout. Furthermore, columns 5 to 9 demonstrate the use of an image, a prompt, and spatial control. This setup highlights the model’s compatibility with pre-trained spatial control models, allowing the InstantID model to flexibly introduce spatial controls using a pre-trained ControlNet component.

It is also critical to acknowledge the impact of the number of reference images on the quality of the generated image, as shown in the above image. While the InstantID framework delivers commendable results with a single reference image, utilizing multiple reference images generally produces higher quality images, as the framework averages the mean of ID embeddings for image prompting. Additionally, it is essential to compare the InstantID framework with previous methods that generate personalized images using a single reference image. The following figure compares the results generated by the InstantID framework with those from existing state-of-the-art models for single-reference customized image generation.

As demonstrated, the InstantID framework excels at preserving facial characteristics because the ID embeddings it utilizes inherently contain rich semantic information, including identity, age, and gender. It is fair to conclude that the InstantID framework surpasses existing frameworks in customized image generation due to its ability to maintain human identity while offering control and stylistic flexibility.

Final Thoughts
In this article, we have explored InstantID, a diffusion model-based solution for image generation. InstantID functions as a plug-and-play module that adeptly manages image generation and personalization across a range of styles using just a single reference image while ensuring high fidelity. The framework is designed for instant identity-preserving image synthesis, aiming to seamlessly bridge the gap between efficiency and high fidelity. By introducing a straightforward plug-and-play module, InstantID allows for effective image personalization with just one facial image, maintaining a high standard of fidelity throughout the process.








Comments (0)
No comments found